An introduction to Machine Learning

Oumnia El Khazzani
over 7 years ago

Machine Learning (ML) has left computer science labs to integrate business operations, marketing, web platforms, utilities, and our everyday devices.
You may not know it, but chances are you have been interacting with machine learning more often than you think: the chatbox of that online store you were interacting with, Siri, product recommendations on Amazon or GMaps updates on public transportation delays.
We interact with machine learning, but little do we know about this revolutionary technology.
Here is an introduction to the technology of the future.
Machine Learning:
Machine learning is a subdivision of Artificial Intelligence. It is the process of teaching a machine a specific algorithm that will allow it to process data autonomously and make predictions based on the data processed.
Machine learning started with humans’ fascination towards artificial intelligence, back in the 50's. British scientist Alan Turing created the Turing test to determine if machines had an intelligence of their own - in other words if a computer could reach the point where a human could not see the difference between a human and the machine anymore.
In the same decade, Arthur Samuel wrote the first machine learning code ever written in the canvas of check games.
The following 30 years mark successive developments in computer intelligence: neural networks for computers, pattern recognition, robotic mobility, Explanation-Based Learning (EBL).
In the 90's, scientists turn their focus for machine learning to processing big sets of data and drawing insights out of them.
In 1997, IBM's algorithm, Deep Blue, beats the human world champion at chess.
In 2006, the expression "deep learning" is created to explain algorithms that recognize patterns/elements in content.
Progress in machine learning keeps growing tremendously: in 2011, Google Brain is as intelligent as the brain of a cat, in 2012 Google's X Lab can browse YouTube videos and find those which contain a specific object.
In 2016, Google's AI algorithm proves that machines have reached a level of intelligence comparable to humans'. The AI repeatedly beats the human champion of Go, a game much more complex than chess.
Artificial Intelligence:
Some call it “the new electricity”. It is definitely a major technology shift of the last century.
AI is Intelligence applied to machines. In more technical terms, AI represents software that behaves in a similar way to human beings.
The specificity of AI lies in the fact that this software can learn by themselves.
The birth of AI goes back to summer 1956 when a group of scientists carry-on research to program computers to behave like humans, meaning, teaching computers to reason like humans.
They taught machines to apprehend and understand the world around them and communicate like humans. The intelligence emerging from this programming is Artificial Intelligence.
Training data:
In machine learning, algorithms have to be trained to be able to behave by themselves and process data. Training data is a set of data used to train the machine.
Testing data:
A set of data used to test the accuracy of the trained algorithm. The testing data cannot be the same as training data, otherwise, it would defeat the purpose of the test.
Model parameters:
Parameters the model learns from the training data, for eg: regression coefficients.
Hyperparameters:
Parameters that are inputted externally by the model creator, for eg: number of trees to include in a random forest (in the case of a random forest model).
Supervised/Unsupervised learning:
ANNs cannot be programmed, instead, they learn. The supervised method uses test data on which the ANN can train, and controlling data allowing to check if the ANN provided the right answer/ behavior. In this type of training, the computer knows what they are looking for in the data set.
The unsupervised method lets the ANN learn and test while learning with the help of a specific mathematical formula (cost function). In this type of learning, the computer deals with the data set autonomously and it has to come up with the data pattern by itself.
The semi-supervised learning is a mix of these two methods: starting with unsupervised, letting the computer come-up with insights/patterns, and then switching to a supervised method.
Classification Models:
Algorithms used to train machines. Each model has its rules, logic, and underlying discipline: statistics, logic, mathematics, geometry.
Decision Trees:
Model using consecutive logical nodes with specific decisions to end-up to a final insight/decision/prediction.
Support vector machines (SVM):
A model that classifies data through hyperplanes (geometry: subspaces with n-1 dimension from the ambient space) used for classification and regression analysis. This model is given a set of data belonging to two categories. The trained model can then assign new data items to one or the other category in a non-probabilistic binary linear way.
Regression:
Statistical model analysis the relationship between variables (dependent and independent). This model is used to come up with predictions based on the relationship between sets of data.
Naive Bayes classification:
A probability-based model using tree structures. The model is called "naive" referring to the independence of the probabilistic hypothesis.
Random Forest:
A step further in terms of efficiency versus the Naive Bayes classification. This model uses multiple trees with randomly selected sets of data. This model is particularly helpful for large sets of data with many features.
Natural Language Processing (NLP):
Tools to allow computers to process big amounts of data in human language format.
This area of computer science finds its genesis in the 50's with language recognition models and translation. An application of NLP are chatbots, algorithms that can converse with humans in a human fashion. Chatbots have quasi-infinite use cases from customer service to hotlines for lonely elderly people.
The introduction of machine learning boosted the capabilities of NLP. From handwritten annotations, the learning process switched to statistical rules and models trained on large corpora of human-written texts.
Recommender Systems:
A system where specific items (products, services, books, places, …) are recommended for users (humans, cars, computers,…). The main application of recommender systems is in online shopping personalization.
Knowledge-based recommenders:
Items and users have attributes which are used by the algorithm to come up with rules to create recommendations.
Content-based recommenders:
The rule is based on items a specific user interacted with (purchased, put in the cart, borrowed, viewed, liked, …). Recommendations are catered to each user.
Collaborative filtering:
Recommendations based on the past interactions of the whole user-base.
Artificial neural network (ANN):
A system inspired by the biological neuronal system structure (the human brain).
The evolution of ANNs transitioned from biology to the field of statistics: these networks are optimized by a training with probabilistic Bayes models. ANNs have an application in the field of statistics, which they enrich by providing fast classifications; as well as an application in AI to which they bring autonomous mechanisms of perception (of the external environment).
ANNs can be used to classify data, perceive patterns, detect anomalies, forecast and predict.
Feedforward network:
An ANN where the data is processed from an entry point to an exit point, always forward (no loops). The system has several layers, but the movement of data processing is always forward.
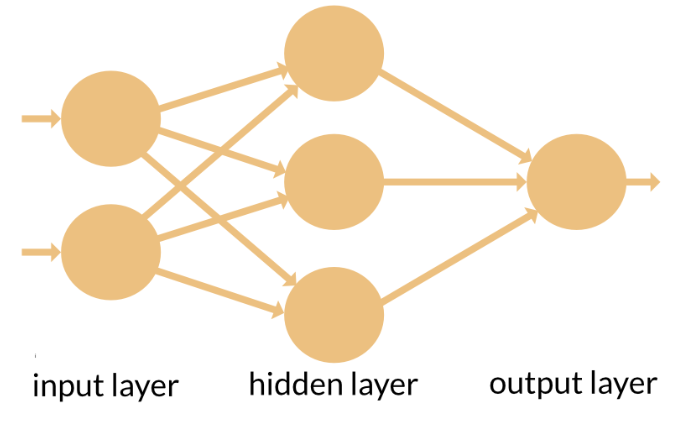
Image source: https://appliedgo.net/perceptron/
Recurrent neural networks (RNNs):
A network of artificial neurons with recurrent connexions, increasing the lifecycle of information. Each neuron is connected in a non-linear way to another one through a synapse with a specific weight. Each connexion can be unfolded to sub connexions (hidden layer). This model is fit to process sequenced information such as temporal series.
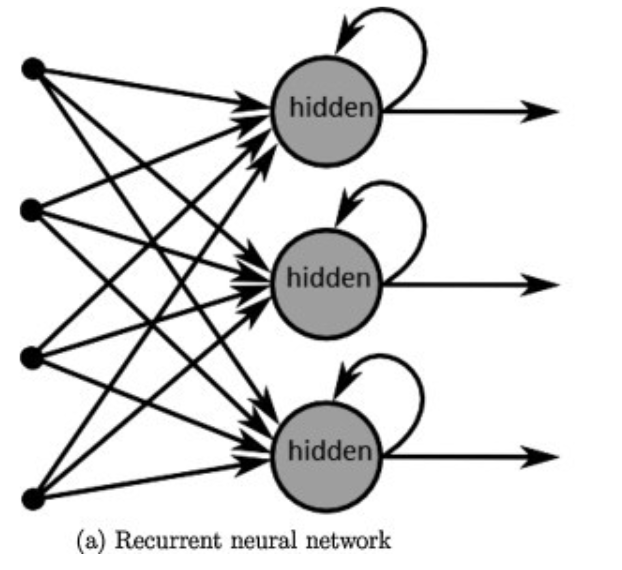
Source : towardsdatascience.com/introduction-to-recurrent-neural-network-27202c3945f3
Long Short-Term Memory (LSTM) Networks:
A kind of RNN with better performance than basic RNNs. RNNs’ ability to link information through loops decreases with the amount of information. If the two pieces of information to be linked are “far away” from each other in the sequence, RNNs have difficulty to establish the connexion. We call this “ long-term dependencies”. LSTMs solve this problem, as they have been designed to remember long-term dependencies.
Convolutional neural networks (CNN, ConvNet):
Artificial and acyclic (feed-forward) neuron network where the connexion between neurons is inspired by animals' visual cortex: they are a stacking of multiple perceptrons that process small amounts of data.
CNNs are mainly applied for video and image recognition, recommendation applications (such as for an online shop) as well as NLP.
The central layer of such a network is called the convolutional layer. It is composed of a series of neurons which create the depth of the layer and treats data coming from their receptive field.
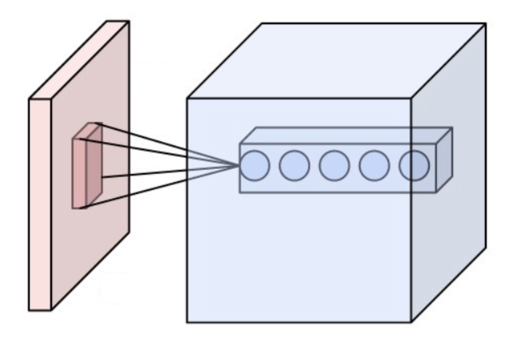 Source: wikipedia.org
Source: wikipedia.org
Data in CNNs is also processed through Pooling which consists of sectioning the input data (an image) into small, separate blocks of data (pixels). Pooling is used to reduce the size of data and the amount of calculation to be performed by convolutional (conv) layers. It is common to see pooling layers inserted between two conv layers.
Reinforcement learning:
A machine learning method in which the agent (machine) learns through experimentation in a set environment. The learning happens through gratification given by the environment when the agent makes the right decision. The agent derives strategies to maximize the gratification, and this is how it learns.
Reinforcement learning is the type of Machine Learning that has been used by machines to beat Worldwide Go, Poker human champions.
Perceptron:
Supervised machine learning algorithm based on a binary function. Another way to call them is “binary classifiers”: algorithms that distribute data among 2 categories in a binary way.
Deep learning:
A subfield of machine learning that uses multiple layers of ANNs. Deep learning algorithms allow the processing of larger amounts of data more efficiently. Deep learning models are also more performant algorithm because of their ability to automatically extract features from data (feature learning).
History in motion - World Chess champion, Gary Kasparov, loses against a machine (Deep Blue).
Dimensionality Reduction:
High dimension data sets present redundancy and little incremental value. It is thus more efficient to reduce the dimensionality of it. Dimensionality reduction is a mathematical process to reduce the number of random values in a set of data. The operation consists of turning data of big dimension and turning it into data of small dimension. Small sized data can be processed quicker. This process goes either through a feature selection -select a subset of the data to make it smaller, or feature extraction - the creation of a derived set of data.
General Adversarial Networks (GANs):
A type of non-supervised learning algorithms allowing to generate very realistic images. The algorithm is based on the game theory, where two networks “play”: the generative network generates an information, and the discriminative network determines if the information is “true data” or if it has been generated by the generative network. GANs are used to generate visuals allowing humans to visualize - interior design, products, constructions, … GANs have lately been applied for videos, as well as photo enhancement.
This wiki was brought to you by the Machine Learning team at Swish. We work with cutting-edge algorithms and AI to solve problems in industries such as Finance, Retail, and Travel. Learn more.
Sources: https://www.forbes.com/sites/bernardmarr/2016/02/19/a-short-history-of-machine-learning-every-manager-should-read/#2cdc0b4515e7 wikipedia https://www.analyticsvidhya.com/blog/2015/07/dimension-reduction-methods/ https://medium.com/recombee-blog/recommender-systems-explained-d98e8221f468 https://appliedgo.net/perceptron/ www.machinelearningmastery.com http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Share this post
© 2018 Swish Labs, Inc. All Rights Reserved.